
Using Document Layout Structure for Efficient RAG
Chunking documents by their logical layout structure improves LLM performance on large documents.

The remarkable capabilities of large language models (LLMs) open up incredible opportunities for analyzing documents at scale. However, making the text in documents, especially large PDFs available for LLM has been a challenge due to the amount of text the LLM can analyze at a time (a.k.a LLM context window). There are broadly two approaches to solve the problem:
Convert documents to raw text and break down the text into small chunks of texts, usually less than the LLM context window size (approx 2000-3000 words).
There is a growing body of research in making LLMs work with much larger contexts that scale up to several hundred pages of text.
Both the options have severe drawbacks, which I will discuss below.
At this point, if you’d like to go straight the solution, here’s the github link.
Naive Chunking
Let’s look at naive chunking. Documents express their meaning through their layout:
Naive Chunking: Section and Subsections
Headings and nested subheadings represent a theme that describes all the text underneath. The picture below illustrates how semantics implied by the nested heading structure in the document is lost with naive chunking that is not aware of the structural boundaries of the document.

Naive Chunking: Lists and Sublists
Chunking lists and sublists can similarly result in loss of semantics implied by document structure as shown below. Sometimes, a page based chunking approach is used to push more into the chunk so that the LLM has access to a larger context. However, as you can see from the picture below, page based chunking also can result in information loss in the context because a list item will be separated from the rest of the list items and lead-in sentence.

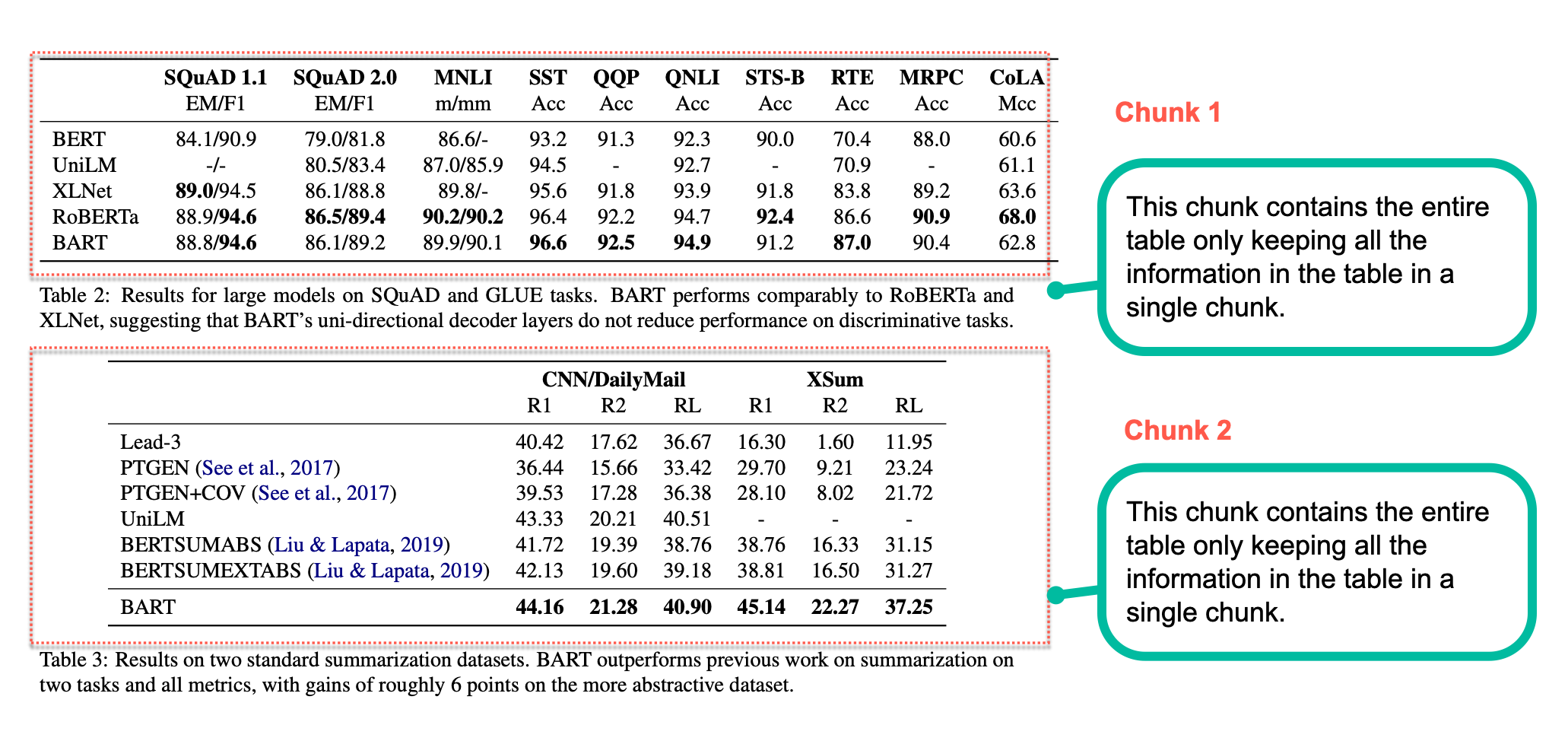
Naive Chunking: Tables
Similarly, in case of tables, not knowing the appropriate boundaries while chunking can result in loss of information and meaning as shown in the picture below.

Smart Chunking
When the document reader/loader is aware of document structure, it can create smart chunks as described in the sections below.
Smart Chunking: Sections and subsections
Smart chunking identifies sections and subsections, along with their respective nesting structure. It merges lines into coherent paragraphs and establishes connections between sections and paragraphs. Note that in the picture below, the main header 3 is repeated along with all its child chunks 3.1, 3.2, 3.3, providing the necessary context to subsections. It provides option to either use the smaller chunks from each subsection or the entire section for LLM analysis.

Optimal Chunking: Lists
Optimal list chunking clubs all the list items into a single chunk and also keeps the first leading paragraph in the context as shown below. This chunking allows LLM to get all the context information it needs in a singe chunk, making the generation accurate. No information is lost because of page splits, or the list items separating from other list items and lead-in sentence.

Optimal Chunking: Tables
Optimal chunking of tables preserves the table layout along with the table headers and subheaders. This opens of the table for a variety of LLM based analsyis of the table data.
What about larger context windows?
In recent months significant research has gone into expanding the context window upto a billion tokens! Anthropic and Cohere have provided document upload APIs. This is indeed an outstanding technical advancement. However the practicality of this solution at scale still remains to be seen. It may be a good solution for summarization type of prompts on a single document, but still not something that can scale to retrieval augmented generation (RAG) over thousands of documents. Optimal chunking of documents and injection of long running contexts from section headers and lead-in sentences provides sufficient information for efficient RAG. It is a cost-efficient and low latency solution.
Enter LayoutPDFReader
The majority of PDF and document readers available today convert a PDF document into plain text blobs. Even if some APIs do provide more information such as box co-ordinates of text blocks in a PDF, they do not parse the heirarchical information and link related chunks of text together to create a complete context for LLMs. Layout aware chunking will propel LLM applications, especially RAG to the next level of usefulness. LayoutPDFReader is a fast reader that splits the text in PDFs into layout aware chunks and provides a convenient way for LLM developers to index and access and analyze different sections of the PDF.
Get started here.
Experiment with it in colab here.
from where will I get "API url for LLM Sherpa"??
The endpoint gives connection pool timeout, not sure if this can be used in production.
WARNING:urllib3.connectionpool:Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7ceb443fa590>, 'Connection to readers.llmsherpa.com timed out. (connect timeout=None)')': /api/document/developer/parseDocument?renderFormat=all